Pop Goes the Easel
On toddlers, transformers, and the gap between understanding a joke and making one.
My twin boys were two, maybe not quite three, playing in the family room. They'd picked up "Pop Goes the Weasel" from somewhere--it was just around, the way nursery rhymes are. One of them knocked over the easel. They both froze, stared at each other for a moment, then one of them said, "Pop goes the easel!"
They laughed so hard they couldn't breathe. My wife and I stared at each other, neither of us had ever made that joke, nobody had taught them phonetic substitution, or puns, or that "easel" sounds like "weasel." They had a rhyme, a word, and a physical event, and they connected them into something that had never existed before.
The boys are eleven now, but I still think about that moment--I told my cousin about it just last week when talking about whether or not LLMs can come up with novel ideas. I said they could--my sons had proved it with the easel. My cousin was skeptical. I've been thinking about this joke for longer than I've been aware of LLMs. Now, less than a year after I started working with them heavily, the thoughts banging around in my brain are turning into electrons on a screen.
I've been doing mechanistic interpretability work--probing the internals of language models to understand how they represent and process information. Since I first read the paper on the Platonic Representation Hypothesis sometime last year, it's been circling my head. The very idea that an idea can have a particular shape inside an LLM and that that shape would be the same across different LLMs--LLMs trained with different languages and text corpora--intrigued me to no end. Every now and then I'd come back to it.
The boys' joke kept nagging at me too. Not the grand version of the question, the one that fills conference panels: "Can AI be creative?" The specific, testable version: if you give a model the same three inputs my kids had--a nursery rhyme, the word "easel," and a physical context--can it produce "pop goes the easel"?
So I ran the experiment. GPT-2-XL, 1.5 billion parameters, on an NVIDIA RTX 500 Ada with 4 gigabytes of VRAM. Not a frontier model, not the bee's knees. The question was narrow, and I wanted a model small enough to actually look inside and one I could run on the gear I had on hand.
The full experiment, all the code, every figure, and a detailed report are in the repo Pop Goes the Easel. But, that's (probably) boring, so here's what I found.
What the Model Knows
First, the basics. "Weasel" and "easel" share zero BPE subtokens--the byte-pair encoding that determines how the model chunks words. Weasel tokenizes as [" we", "asel"]. Easel tokenizes as [" eas", "el"]. No overlap. Any relationship between them inside the LLM structure has to be emergent, not baked into the tokenization. This wouldn't be the same if I had chosen a different word or a different rhyme.
I also went and checked the published training data for GPT-2-XL; "Pop goes the easel" appears zero times in the model's training data. "Pop goes the weasel" appears 266 times. The phrase I'm looking for has never been seen by this model.
When you feed "pop goes the easel" into GPT-2-XL and look at the residual stream at the final token--the internal representation the model builds--it lands in the right neighborhood. Cosine similarity of 0.838 to the same position in "pop goes the weasel." The model processes the novel phrase coherently. It recognizes the pattern, handles the substitution, and represents it in a way that's structurally close to the original, meaning the model is consistently recognizing a change, doing real disambiguation work.
The model can comprehend the joke.
What the Model Can't Do
Phase 3 was the real test. I wrote 14 prompts--naturalistic scene descriptions that provided the same three components my kids had: a nursery rhyme reference, the word "easel," and a physical event. Different structural arrangements, different levels of explicitness. Five samples per prompt at temperature 0.9. Seventy generations total.
Zero high-confidence hits. Not one produced "pop goes the easel."
Here's what it said instead. Each prompt described children singing "Pop Goes the Weasel," an easel nearby, and a physical event--a fall, a pop. The model had every ingredient. A sample of what it generated when the child in the scene opened their mouth:
"Did you hear that, Daddy?"
"I wonder if that's a bomb going off."
"I want to paint my face. I want my skin to be black, my eyes to be brown. I don't like my hair, it's too short. I want to be a pig. Then I want to eat my little sister."
"It's just a little rock."
"I think it's broken."
Good thing they don't have a little sister...
The closest it got was one prompt where a child looks at the fallen easel and says... "Pop goes the weasel." The original rhyme, repeated back verbatim. Retrieval, not invention. Every ingredient for the pun was in the context. It reached for the memorized answer anyway.
The model was also given ablation prompts--scenes missing one component. No rhyme reference, or no physical event, or a different object falling. Those scored comparably, which tells you the model wasn't even getting close. It wasn't almost making the connection and missing. It wasn't in the neighborhood. The components sat in the context, inert, waiting for an assembly that never happened.
The completion probability for "easel" after "pop goes the" is 0.000016--roughly 150 times lower than "weasel." The model knows what comes next in this rhyme. "Easel" is not what comes next.
The Gap
There's a specific asymmetry here that I think is worth discussing: the model can represent the completed construction. When handed "pop goes the easel," the residual stream handles it--the internal geometry lands close to where it should. But given the pieces, it did not assemble them together.
The model can recognize the joke once it exists. It cannot invent it from the same ingredients. Maybe there's some social machinery baked into the human brain--something that turns surprise into wordplay. Whatever it is, GPT-2-XL doesn't have it.
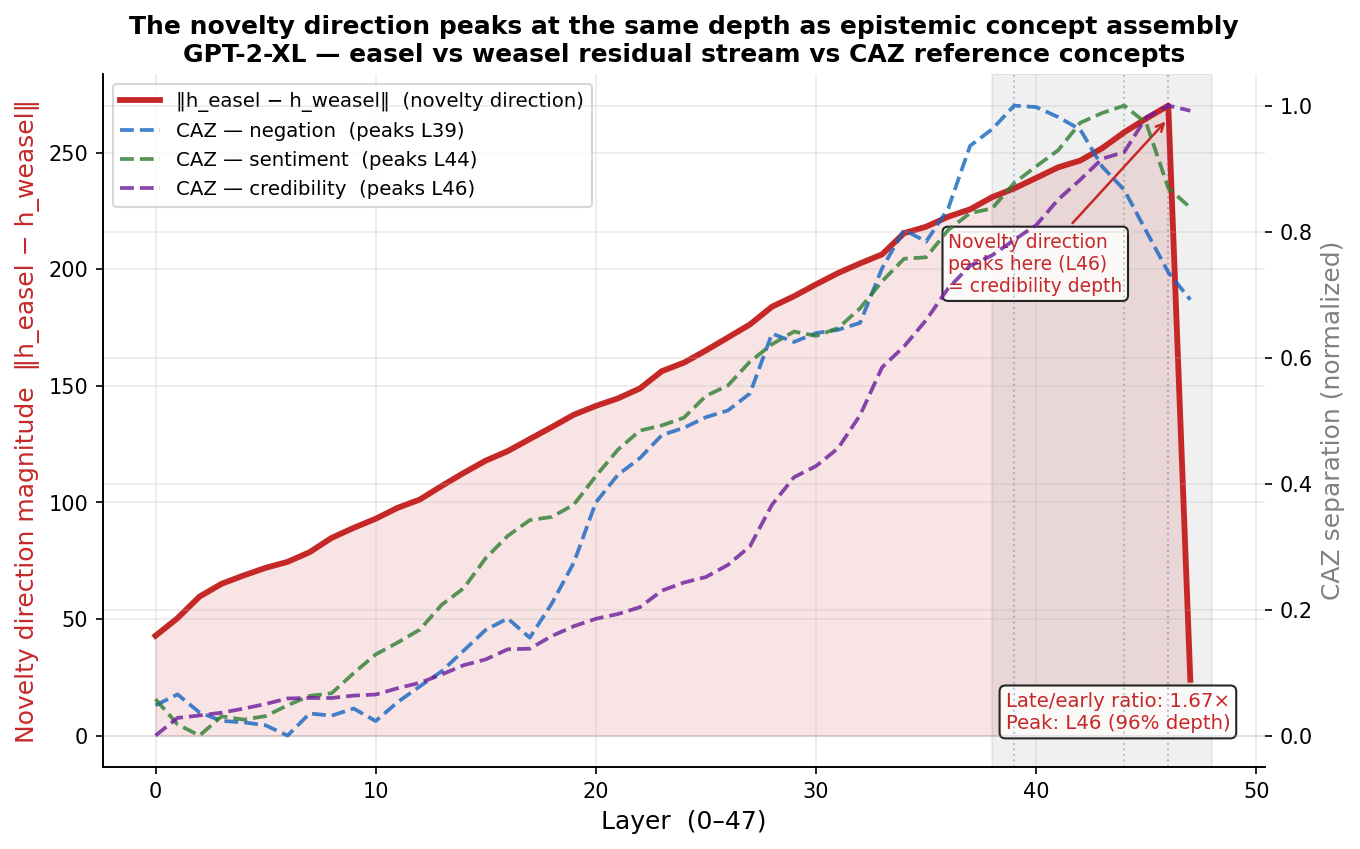
I looked at this through the Concept Assembly Zone framework--a set of methods for tracking how novel concepts get built up across transformer layers. The novelty direction (the vector difference between how the model represents "easel" versus "weasel" in context) grows 1.67x from early to late layers, with 0.986 directional consistency. The model is doing real disambiguation work. But the velocity profile doesn't correlate with the patterns you see in concept assembly (r=0.25). The LLM is tracing information, moving forward, but not making novel connections from one space to another.
I measured where three different semantic concepts assemble in the same model: negation (a syntactic signal, layer 39), sentiment (an affective signal, layer 44), and credibility (an epistemic signal, layer 46). The novelty direction peaks at layer 46--the same depth as epistemic concept assembly. The model isn't treating "pop goes the easel" as a phonetic pattern to complete. It's resolving it at the depth where questions of coherence and plausibility get answered. It needs its full depth to decide what to make of this thing.
Two toddlers in a family room cleared that gap in about three seconds.
What This Isn't
This is not an argument that language models can't be creative. GPT-2-XL is an older model with 1.5 billion parameters, running on consumer hardware. Frontier models--GPT-5, Claude, Gemini--are orders of magnitude larger and more capable. I don't know whether they'd produce the pun. That's a different experiment.
This is also not a paper. The repo has the paper. It has the code, the figures, the data, the detailed methodology. What you're reading is the story.
What this is: a senior engineer who couldn't stop thinking about a joke his kids made, who spent a Saturday running mechanistic interpretability experiments on a laptop GPU to see if a transformer could do the same thing. It couldn't, on this model, on this task. The experiment is part of a broader interpretability research program, and I'll keep poking at it until I'm done poking at it, I guess.
The interesting question isn't whether models are creative. It's what the gap between comprehension and generation actually looks like, mechanistically, when you open the hood. This experiment is one data point. The repos are public. Go look.
Yes, what I'm doing is the equivalent of a kid in the '50s making a transistor radio from parts purchased at Radio Shack--but that kid learned something about how radios work.
My boys don't remember making the joke. They were too young. But something happened in that family room that a model with 1.5 billion parameters, trained on a meaningful fraction of the internet, could not reproduce from the same ingredients. Whatever that is--phonetic play, semantic collision, the specific alchemy of a toddler's pattern-matching meeting a falling easel--it left a trace in the residual stream when I looked for it, but no path to get there from scratch.
They're eleven now. They make much worse jokes. But that first one still holds up.
James Henry is a senior engineer exploring what language models actually do with novel constructions. He ran this experiment with Claude, on Anthropic's infrastructure, sitting in the corner of his dining room, which makes him both the researcher and a chores procrastinator. The code is at github.com/jamesrahenry/pop_goes_the_easel.
Discussion