The Shape of Thought
What happens when you stop looking for concepts and start watching them form.
In March I published a post about a joke my toddlers made--"pop goes the easel"--and whether a language model could reproduce it from the same ingredients. Turns out, it couldn't. But along the way I mentioned a framework I'd been building: the Concept Assembly Zone. I used it to look at where the model processed the novel phrase, and found that it resolved "pop goes the easel" at the same depth where epistemic reasoning happens--layer 46 of 48. The model needed nearly its full depth to decide what to make of a toddler pun.
That was one model, one phrase, one question. Since then I've run the framework across 34 models from 8 architectural families--Pythia, GPT-2, OPT, Qwen, Gemma, Llama, Mistral, Phi--spanning 70 million to 7 billion parameters. This post is about what the framework found.
The Snapshot Problem
The standard approach in mechanistic interpretability is to find the "best layer"--the single depth in a model where a concept is most visible. You pick the layer where a linear probe or a difference-of-means vector achieves maximum class separation, extract your concept direction, and move on.
This works. It's computationally efficient and empirically grounded. It also captures a snapshot of a process rather than the process itself.
Transformers are iterative. Each layer reads from and writes to a shared residual stream--a running total of everything the model has computed so far. A concept that's visible at layer 15 was shaped by layers 10 through 14 before it. The best-layer approach tells you where the concept is most legible. It doesn't tell you how it got there.
Concept Assembly Zones
[Update: I've since renamed this to Concept Allocation Zone — "allocation" better captures what the measurement tracks. The abbreviation CAZ and all the analysis remain the same.]
The CAZ framework tracks concept formation across every layer using three main measurements.
Separation High separation means the model's activations for credible and non-credible text have moved far apart. Low separation means they're still jumbled together.
Coherence High coherence means the model has committed to one dominant direction for the concept--it's crystallized into a sharp geometric feature. Low coherence means the separation exists but it's diffuse.
Velocity Positive velocity means separation is increasing--the model is actively constructing the concept at this layer. Zero means nothing is changing. Negative means the concept is being degraded or reallocated.
The three together track concept assembly--where construction begins, where it peaks, and where the geometry gets repurposed for something else.
So I took the idea of the CAZ and I made some predictions, among them that concepts as represented by CAZes would have consistent ordering, that abstract concepts would have wider CAZes, that shallow peaks would encode words and deeper peaks would encode concepts, and that the highest peak would dominate the inference run. Some of these predictions bore fruit--that last one absolutely did not.
Peaked my Interest
The first thing the framework revealed is that the separation curve--the profile of how visible a concept is across layers--is frequently multimodal. Multiple peaks, not one. A single concept can produce significant assembly events at several different depths.
This matters because the standard approach assumes one peak. If you're only looking for the single best layer, you're discarding everything else. And "everything else" turns out to be causally active.
The scored detection method uncovered a category of subtle assembly events I'm calling gentle CAZes--peaks so small they fall below standard detection thresholds. They look like noise but they aren't. Ablation testing--surgically removing the concept direction at those layers and measuring the behavioral effect--confirms that 95% of gentle CAZes are doing real work. There's signal in the weeds and that signal has a real effect on the outcome of the inference run.
Running the detector at full sensitivity on GPT-2-XL alone increased detected assembly events from 7 to 30. Those 23 additional events aren't useless artifacts. Those events are part of the construction process that the snapshot approach was never designed to see.
Here's what that looks like in practice. The interactive cazstellation below shows the full CAZ profile for GPT-2-XL--the same model from the Pop Goes the Easel experiment--across all seven concepts. Each row is a concept; each dot is a detected assembly event, sized by score and colored by type. The gentle CAZes are the small ones. They're everywhere.
I spent more time than I should have building cazstellations--interactive 3D maps of concept assembly across models. The most fun representation shows CAZ representations across all 21 models and looks like dragons inflight--I posted this one to a bunch of people because it's pretty. But the pretty things you see along the way are part of the process, and the full gallery is up if you want to spin them around. The CAZstellations, as I called them, are gorgeous but they're also mostly meaningless--it turns out that four thousand dimensions do not squeeze down into three and show you anything of value.
I kept playing with things and eventually other visualizations did earn their keep. The labeled dark matter maps and universal feature atlas surfaced something the statistics hadn't: some geometric directions don't align with any single concept. Instead, they cycle through concepts across depth--carrying causation at one layer, certainty at the next, credibility later. We found 47 relay features across 20 models, in every family we tested. They're not content; they might be infrastructure--shared geometric channels that the model reuses as it assembles different concepts at different depths. We're calling them relay features, and we don't yet know what they are.
The Ordering
Within a single model, different concepts assemble at different depths, and they do so in a consistent order. Credibility--whether a source is trustworthy--resolves earliest, often from surface lexical cues in the first 40% of depth. Syntactic concepts like negation crystallize next, around 50%. Relational concepts--causation, temporal order--follow in the mid-50s. Affective and evaluative concepts--sentiment, certainty, moral valence--assemble deepest, in the 62-68% range. More abstract concepts produce wider assembly zones; concrete ones are tighter.
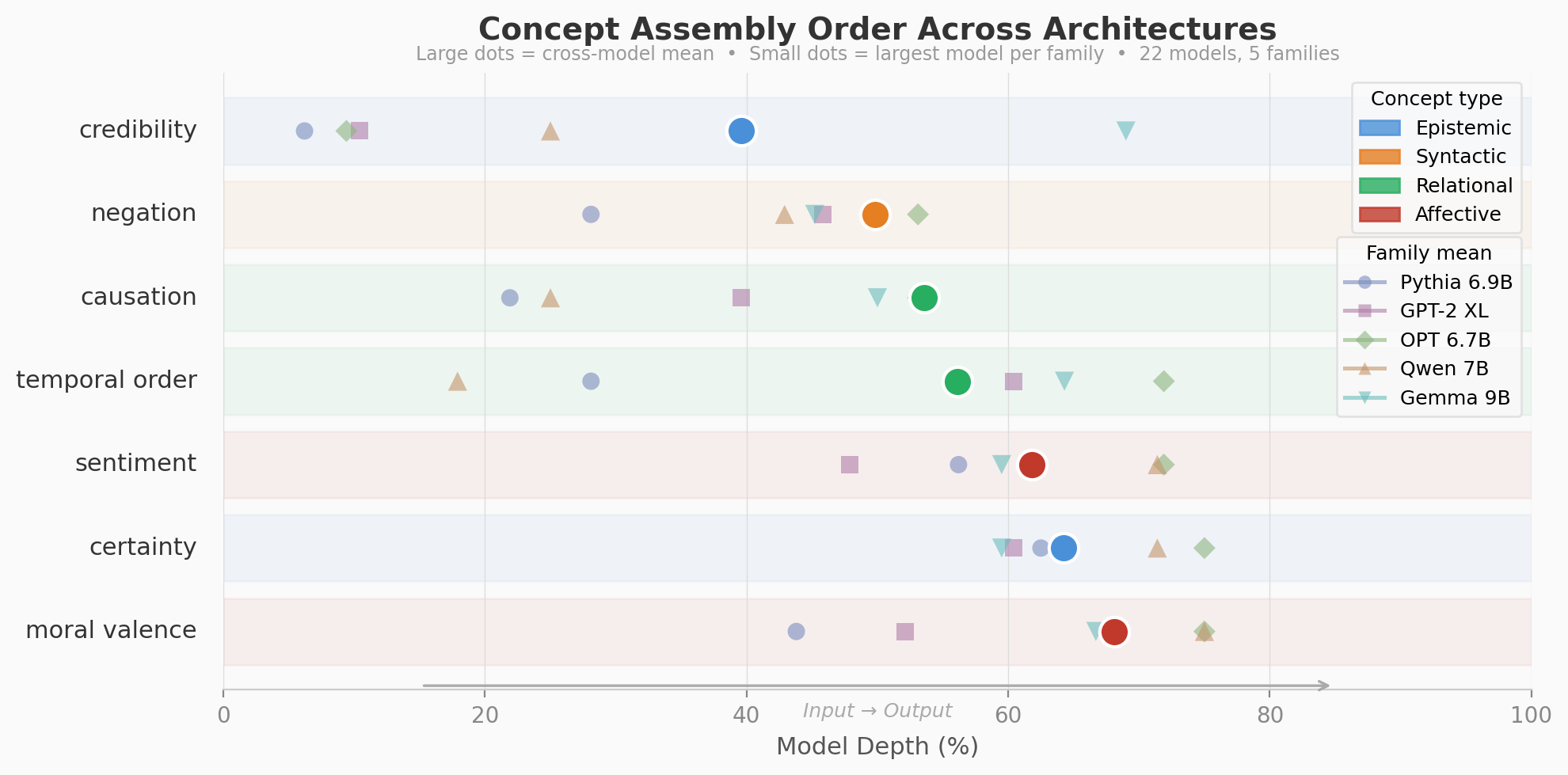
That ordering is not surprising on its own. What's surprising is that it holds across architectures.
Qwen, Gemma, Llama, Mistral--different attention mechanisms, different activation functions, different training data. The absolute layer numbers change. The relative ordering of concept assembly stays the same. Credibility before negation. Negation before sentiment. Sentiment before moral valence. Twenty-five of 26 base models. The sole exception--Phi-2, trained on synthetic textbooks rather than natural text--inverts the order entirely, which may be the kind of exception that proves the rule.
Different models, trained independently, organize their internal representations in the same sequence.
I'm not going to bury the lede on what I think this connects to. The Platonic Representation Hypothesis--the idea that models trained on different data converge on shared representations--has been one of the most interesting open questions in the field and has captured my imagination since I first heard about it. The CAZ results suggest that convergence isn't monolithic. It's layered--shallow representations converge on their own, deep ones converge on their own. Deep representations--the compositional, abstract ones--show the strongest cross-architecture alignment.
The evidence starts here: 34 models, 8 families, a shared tendency that is statistically unmistakable (z = 11.5, p < 0.001) even if individual models don't follow the order perfectly.
From Cazstellations to Reality
A necessary disclaimer: I am not a full-time researcher. I'm a security consultant who does this on evenings and weekends with whatever resources I have available to me and whatever LLM is willing and able to help (token donations accepted! Enquire within.). The CAZ framework, the tooling, and the results have all the peer review of some guy in his bath robe trying to prove that gravity is a push to a physicist eating lunch in a hotel lobby. I've tried to be rigorous. I've tried to be honest about where the evidence is thin. I have not yet had anyone clueful my work except me and the models I collaborate with, and that should inform how much weight you give any of this.
The full paper, the github repo, and the tooling are public. The interactive visualizations are live. Go look.
The interpretability field has been good at anatomy--identifying where things are. The Concept Assembly Zone is an attempt at physiology--tracking how things form. CAZes are about the process that builds the representation across all of the inference run, piece by piece. And, maybe, they make sense--or maybe they just make pretty pictures of dragons.
That's the excitement of this whole endeavour--the number of times I've looked at results and said "What's that?!?" and then had to dig in and find a new rabbit hole has been engaging.
And the discoveries are still coming.
James Henry is a senior security consultant and independent interpretability researcher. He built the CAZ framework on a laptop GPU because he wanted to know how a toddler pun moves through a transformer. The paper, the code, and all the pretty, mostly useless visualizations are public. He writes weekly at waypoint.henrynet.ca.
Discussion